机器学习中的计算图
Computational Graph
Background
早期的机器学习框架主要是针对较为简单的全连接(e.g FNN)和卷积神经网络设计,这些神经网络模型的结构比较简单,神经网络层之间串行连接,我们很容易分析出数据流过神经网络模型时的计算过程。因此,这样的固定计算过程可以用简单的配置文件来定义,一旦给定这样的配置文件,我们就可以清楚地表达出模型定义。
随着日益复杂的机器学习模型的出现(生成对抗网络、注意力模型等),不能再通过简单地直接定义算子的使用过程来表达一个模型(例如带有分支和循环的结构的模型)。机器学习框架需要能够高效分析出算子的执行依赖关系,并进行梯度计算及管理训练参数,以优化计算策略和自动化梯度计算。计算图就是这样一个通用的数据结构来理解、表达和执行机器学习模型,提高机器学习框架训练复杂模型的效率。
Composition of computational graph
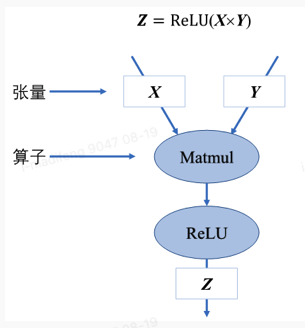
计算图的基本构成是基本数据结构张量(tensor)和基本运算单元算子构成。
算子包括很多类型:算子是构建神经网络的基础,可以理解为一种低级API。通过对算子的封装可以实现各类神经网络层,当开发神经网络层遇到内置算子无法满足时,就可以使用自定义算子来实现。它们可以对张量数据进行加工处理,实现机器学习中的各种常用的计算逻辑。可以按照功能将算子分为:张量操作算子、神经网络算子、数据流算子和控制流算子等。例如卷积(convolution)、池化(pooling)、全连接(Fully Connected)等。计算图中使用节点来表示算子,节点间的有向边来表示张量的状态,也描述了算子间的依赖关系。
张量
张量其实就是指多维数据,使用秩来表示张量的维度。例如,标量为0维张量,向量为一维张量。在一般的机器学习框架中,张量不仅需要存储数据,还需要存储张量的数据形状、数据类型、秩、存储位置和梯度传递状态等多个属性。
一般来说,在机器学习的环境下,张量的形状一般是“整齐”的,也就是每个轴具有相同的元素个数(e.g
一个矩形/一个立方体),而有时为了节省内存也会使用不规则张量和稀疏张量。
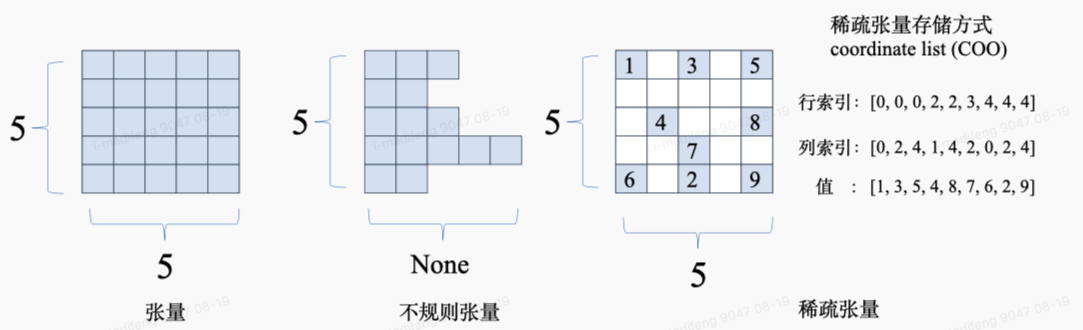
稀疏张量一般应用在图数据与图神经网络中,采用特殊的存储格式(如coordinate list,COO),高效存储稀疏数据以节省存储空间。Calculate dependencies
计算图存在依赖关系,这种依赖关系影响的是算子的执行顺序与并行情况。循环依赖的数据流向在机器学习算法中是不被允许的,它会形成计算逻辑上的死循环,使得模型的训练程序无法正常结束,造成数据趋向于无穷大或者0成为无效数据。
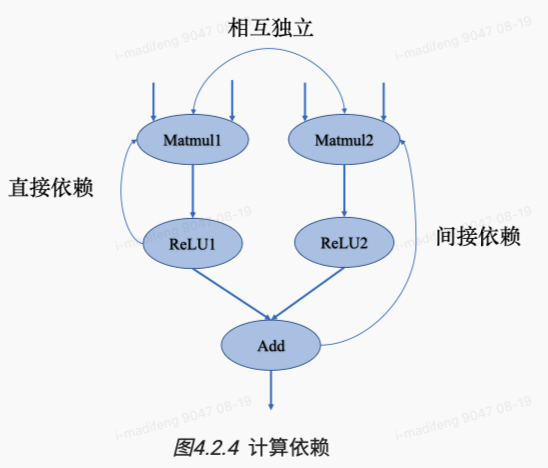 根据依赖关系,我们可以知道某些节点必须等待其前继节点的计算任务完成后才能开始,因此需要避免此类节点之前的节点被删除或更改。
## Cyclic unfolding 对于存在循环关系的计算图,一般使用展开机制来实现。
根据依赖关系,我们可以知道某些节点必须等待其前继节点的计算任务完成后才能开始,因此需要避免此类节点之前的节点被删除或更改。
## Cyclic unfolding 对于存在循环关系的计算图,一般使用展开机制来实现。
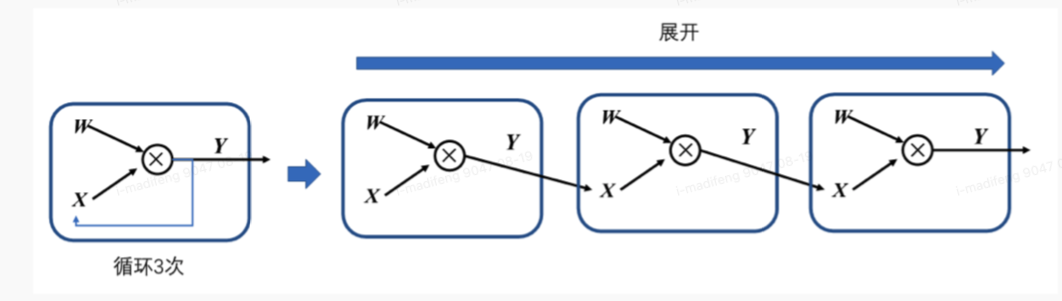 循环体中的计算子图会按照迭代次数进行复制,将展开的子图进行串联,相邻迭代轮次的计算子图是直接依赖的关系。由于在计算图中,每一个张量和运算符都有唯一的标识符,即使是相同的运算符在不同迭代的计算任务中也会有不同的标识符。这样可以对展开后的子图中的计算节点赋予独特的标识符来避免循环依赖。
循环体中的计算子图会按照迭代次数进行复制,将展开的子图进行串联,相邻迭代轮次的计算子图是直接依赖的关系。由于在计算图中,每一个张量和运算符都有唯一的标识符,即使是相同的运算符在不同迭代的计算任务中也会有不同的标识符。这样可以对展开后的子图中的计算节点赋予独特的标识符来避免循环依赖。
Control flow
通过控制流可以设定特定的顺序来执行计算任务,让某些计算节点执行任意次数或者根据条件判断某些节点不执行。常见的控制流分为条件分支和循环两种,当模型包含控制流时,梯度在反向传播时应能在反向梯度计算图中也构造出相应的控制流,才能正确地计算参与运算的张量的梯度。
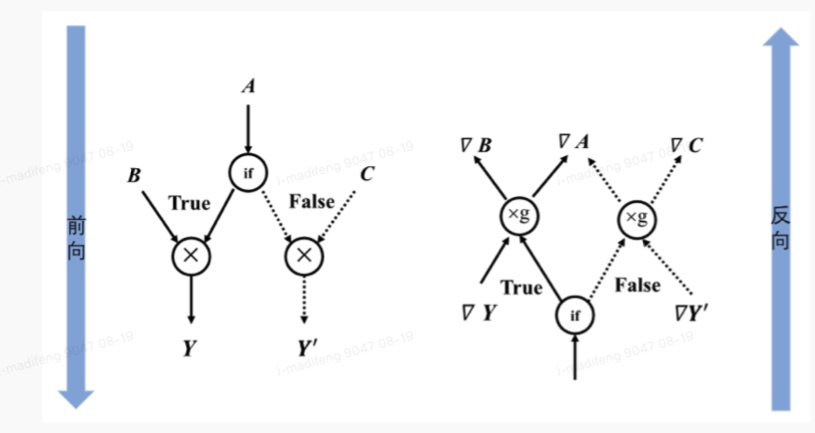 可以想到,当模型中含有循环控制时,每一次的循环都依赖于前一次循环的计算结构,所以循环控制中还需要维护一个张量列表用来将循环迭代中的中间结果缓存起来,用来参与前向计算和梯度计算。
可以想到,当模型中含有循环控制时,每一次的循环都依赖于前一次循环的计算结构,所以循环控制中还需要维护一个张量列表用来将循环迭代中的中间结果缓存起来,用来参与前向计算和梯度计算。
generation of computational graph
在机器学习框架中,计算图可以分为静态图和动态图两种。
静态图:静态生成可以根据前段语言描述的神经网络拓扑结构以及参数变量信息来进行构建,静态图执行期间可以不依赖前端语言描述,因此常用于模型部署。
动态图:动态图在每一次执行神经网络模型时都需要依据前段语言描述生成一份临时的计算图,因此计算图的动态生成过程灵活可变,有助于神经网络结构的调整。
static generation
静态的计算图的生成与执行采用先编译后执行的方式,将图的定义和执行分离。
 前端语言定义模型后,机器学习框架会首先对神经网络模型进行分析,获取网络层之间的拓扑关系以及参数变量设置、损失函数等信息。然后框架会将完整的模型编译为可被后段计算硬件调用执行的固定代码文本,也即静态计算图。
前端语言定义模型后,机器学习框架会首先对神经网络模型进行分析,获取网络层之间的拓扑关系以及参数变量设置、损失函数等信息。然后框架会将完整的模型编译为可被后段计算硬件调用执行的固定代码文本,也即静态计算图。
当使用静态计算图进行模型训练或者推理时,无需再编译前端语言模型。静态计算图直接接收数据并通过相应硬件调度来执行图中的算子完成任务。
机器学习框架在进行静态编译时并不读取输入数据,而是使用一种特殊的张量来表示输入数据,辅助构建完整的计算图,这种特殊张量也就被称为:数据占位符(placeholder).所谓的数据占位符其实就是定义的数据变量(e.g X Y)。
前端定义需要声明并编写包含数据占位符、损失函数、优化函数、网络编译和执行环境以及网络执行器等在内的预定义配置项。静态计算图的优势在于计算性能和直接部署。静态图在机器学习框架编译时就能够获取模型完整的图拓扑关系。而掌握全局信息则更容易制定计算图的优化策略。部署模型进行应用时,可以将静态计算图序列化保存,这在模型推理时就可以执行序列化的模型而不必再重新编译前端语言代码。
disadvantages
前端语言构建的神经网络模型经过编译后,计算图的结构就会固定执行且不再改变,经过优化后的用于执行的静态图代码也与原始代码存在较大差距。因此,在执行过程中发生错误时,会返回优化后代码出错的位置,用户难以查看优化后的代码,这会增大代码调试的难度。
dynamic generation
动态图采用解析式的执行模型,其核心特点是编译与执行同时发生。
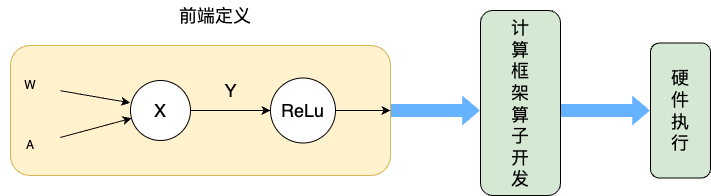 动态图会采用前端语言自身的解释器来对代码进行解析,利用机器学习框架本身的算子分发功能,即刻执行并输出输出结果。该过程并不产生静态的计算图,而是按照前端语言描述模型结构,按照计算依赖关系进行调度执行,动态生成临时的图拓扑结构。
动态图会采用前端语言自身的解释器来对代码进行解析,利用机器学习框架本身的算子分发功能,即刻执行并输出输出结果。该过程并不产生静态的计算图,而是按照前端语言描述模型结构,按照计算依赖关系进行调度执行,动态生成临时的图拓扑结构。
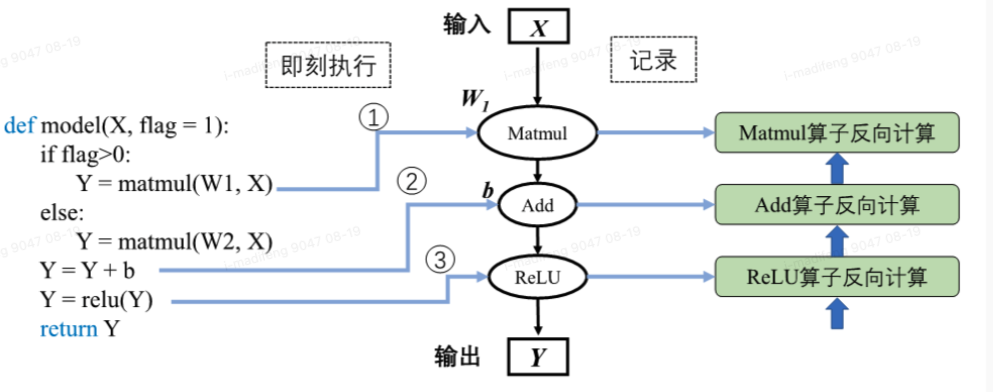 具体来说,神经网络前向计算按照模型声明定义的顺序进行执行。当模型接收输入数据X后,机器学习框架开始动态生成图拓扑结构,添加输入节点并准备将数据传输给后续节点。当模型中存在条件控制时,动态图模式下会即刻得到逻辑判断结果并确定数据流向。机器学习框架会在添加节点的同时完成算子分发计算并返回计算结果,同时做好准备向后续添加的节点传输数据。当模型再次进行前向计算时,动态生成的图结构则失效,并再次根据输入和控制条件生成新的图结构。相比于静态生成,可以发现动态生成的图结构并不能完整表示前端语言描述的模型结构,需要即时根据控制条件和数据流向产生图结构。由于机器学习框架无法通过动态生成获取完整的模型结构,因此动态图模式下难以进行模型优化以提高计算效率。
具体来说,神经网络前向计算按照模型声明定义的顺序进行执行。当模型接收输入数据X后,机器学习框架开始动态生成图拓扑结构,添加输入节点并准备将数据传输给后续节点。当模型中存在条件控制时,动态图模式下会即刻得到逻辑判断结果并确定数据流向。机器学习框架会在添加节点的同时完成算子分发计算并返回计算结果,同时做好准备向后续添加的节点传输数据。当模型再次进行前向计算时,动态生成的图结构则失效,并再次根据输入和控制条件生成新的图结构。相比于静态生成,可以发现动态生成的图结构并不能完整表示前端语言描述的模型结构,需要即时根据控制条件和数据流向产生图结构。由于机器学习框架无法通过动态生成获取完整的模型结构,因此动态图模式下难以进行模型优化以提高计算效率。
在静态生成方式下,由于已经获取完整的神经网络模型定义,因此可以同时构建出完整的前向计算图和反向计算图。而在动态生成中,由于边解析边执行的特性,反向梯度计算的构建随着前向计算调用而进行。在执行前向过程中,机器学习框架根据前向算子的调用信息,记录对应的反向算子信息以及参与梯度计算的张量信息。前向计算完毕之后,反向算子与张量信息随之完成记录,机器学习框架会根据前向动态图拓扑结构,将所有反向过程串联起来形成整体反向计算图。最终,将反向图在计算硬件上执行计算得到梯度用于参数更新。
尽管动态生成中完整的网络结构在执行前是未知的,不能使用静态图中的图优化技术来提高计算执行性能。但其即刻算子调用与计算的能力,使得模型代码在运行的时候,每执行一句就会立即进行运算并会返回具体的值,方便开发者在模型构建优化过程中进行错误分析、结果查看等调试工作。
Advanced tool
目前TensorFlow、MindSpore、PyTorch、PaddlePaddle等主流机器学习框架为了兼顾动态图易用性和静态图执行性能高效两方面优势,均具备动态图转静态图的功能,支持使用动态图编写代码,框架自动转换为静态图网络结构执行计算。
动态图转换为静态图的实现方式有两种:
- 基于追踪转换:以动态图模式执行并记录调度的算子,构建和保存为静态图模型。
- 基于源码转换:分析前端代码来将动态图代码自动转写为静态图代码,并在底层自动帮用户使用静态图执行器运行。
trace transition
基于追踪转换的原理相对简单,当使用动态图模式构建好网络后,使用追踪进行转换将分为两个阶段。
第一个阶段与动态生成原理相同,机器学习框架创建并运行动态图代码,自动追踪数据流的流动以及算子的调度,将所有的算子捕获并根据调度顺序构建静态图模型。与动态生成不同的地方在于机器学习框架并不会销毁构建好的图,而是将其保存为静态图留待后续执行计算。
第二个阶段,当执行完一次动态图后,机器学习框架已生成静态图,当再次调用相同的模型时,机器学习框架会自动指向静态图模型执行计算。追踪技术只是记录第一次执行动态图时调度的算子,但若是模型中存在依赖于中间结果的条件分支控制流,只能追踪到根据第一次执行时触发的分支。此时构建的静态图模型并不是完整的,缺失了数据未流向的其他分支。在后续的调用中,因为静态模型已无法再改变,若计算过程中数据流向缺失分支会导致模型运行错误。同样的,依赖于中间数据结果的循环控制也无法追踪到全部的迭代状态。
code transition
基于源码转换的方式则能够改善基于追踪转换的缺陷。基于源码转换的流程经历两个阶段。
第一个阶段,对动态图模式下的代码扫描进行词法分析,通过词法分析器分析源代码中的所有字符,对代码进行分割并移除空白符、注释等,将所有的单词或字符都转化成符合规范的词法单元列表。接着进行语法分析即解析器,将得到的词法单元列表转换成树形式,并对语法进行检查避免错误。
第二阶段,动态图转静态图的核心部分就是对抽象语法树进行转写,机器学习框架中对每一个需要转换的语法都预设有转换器,每一个转换器对语法树进行扫描改写,将动态图代码语法映射为静态图代码语法。其中最为重要的前端语言控制流,会在这一阶段分析转换为静态图接口进行实现,也就避免了基于追踪转换中控制流缺失的情况。转写完毕之后,即可从新的语法树还原出可执行的静态图代码. # Sceduler of computational graph 模型的训练过程就是计算图中算子的调度执行过程。宏观来看训练任务是由设定好的训练迭代次数来循环执行计算图,此时需要优化迭代训练计算图过程中数据流载入和训练(推理)执行等多个任务之间的调度策略。微观上单次迭代需要考虑计算图内部的调度执行问题,根据计算图结构、计算依赖关系、计算控制分析算子的执行调度。
Execute
算子的调度执行包含两个步骤:
- 第一步,根据拓扑排序算法,将计算图进行拓扑排序得到线性算子调度序列; -
第二步,将序列中国的算子分配到指令流进行计算,并尽可能并行计算。
我们已经知道,计算图是一种由依赖边和算子构成的有向无环图,必须保证算子执行时的依赖关系不被打破。
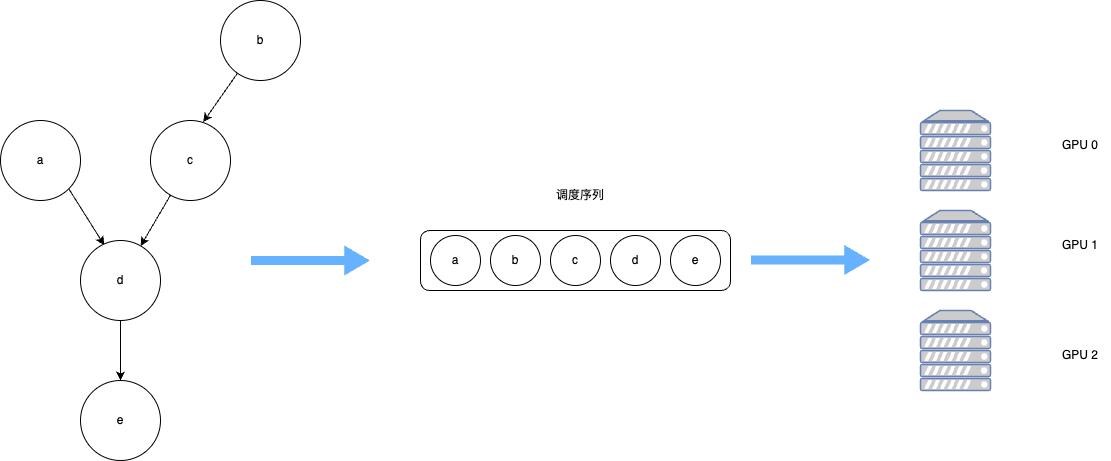
拓扑排序就是不断将入度为0的节点取出放入队列中直至有向无环图中的全部节点都加入到队列中。生成调度序列之后,需要将序列中的算子与数据分发到指定的GPU/NPU上执行运算。根据算子依赖关系和计算设备数量,可以将无相互依赖关系的算子分发到不同的计算设备,同时执行运算,这一过程称之为并行计算,与之相对应的按照序贯顺序在同一设备执行运算被称为串行计算。
Serial and parallel
- 串行:队列中的任务必须按照顺序进行调度执行直至任务队列结束、
- 并行:队列中的任务可以同时进行调度执行,加快执行效率。
Serial
微观上。计算图中大多数算子之间存在直接依赖或者间接依赖关系,具有依赖关系的算子间任务调度则必定存在执行前后的时间顺序。算子的执行队列只能以串行的方式进行调度,保证算子都能正确接受到输入数据,才能完成计算图的一次完整执行。
宏观上,每一轮迭代中计算图必须读取训练数据,执行完整的前向计算和反向梯度计算,将图中所有参数值更新完毕后,才能开始下一轮的计算图迭代计算更新。所以“数据载入-数据预处理-模型训练”的计算图整体任务调度是以串行方式进行的。
Parallel
计算图内部,算子除了直接依赖和间接依赖之外,还存在算子间相互独立的情况。此时可以将算子分配到不同的硬件上进行并行计算。并行包括算子并行、模型并行以及数据并行。
- 算子并行不仅可以在相互独立的算子间实现,同时也可以将单个算子合理的切分为相互独立的多个子操作,进一步提高并行性。
- 模型并行就是将整体计算图进行合理的切分,分配到不同设备上进行并行计算,缩短单次计算图迭代训练时间。
- 数据并行则同时以不同的数据训练多个相同结构的计算图,减少训练迭代次数,加快训练效率。
Synchronous and asynchronous
我们可以将一次完整计算图的训练执行过程分为三个阶段:数据载入、数据预处理和网络训练。这三个环节之间的任务调度是以串行方式进行,每一个环节都有赖于前一个环节的输出。但对计算图的训练是多轮迭代的过程,多轮训练之间的三个环节可以用同步与异步两种机制来进行调度执行。(其实就相当于流水线)
- 同步:顺序执行任务,当前任务执行完后会等待后续任务执行情况,任务之间需要等待、协调运行;
- 异步:当前任务完成后,不需要等待后续任务的执行情况,可继续执行当前任务下一轮迭代。
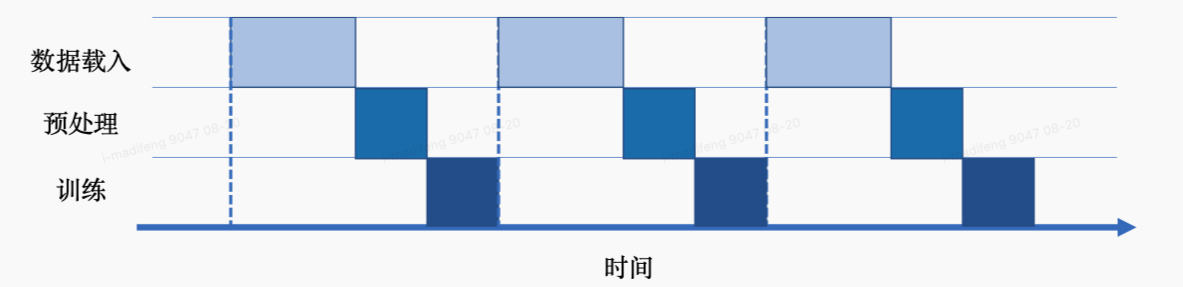
以同步机制来执行计算图训练时,每一轮迭代中,数据载入后进行数据预处理操作,然后进行训练。每一个环节执行完当前迭代中的任务后,会一直等待后续环节的处理,直至计算图完成一次迭代训练更新参数值后,才会进行下一轮迭代的数据载入、数据预处理以及网络训练。也就是说,当进行数据载入时,数据预处理、模型训练处于等待的状态;
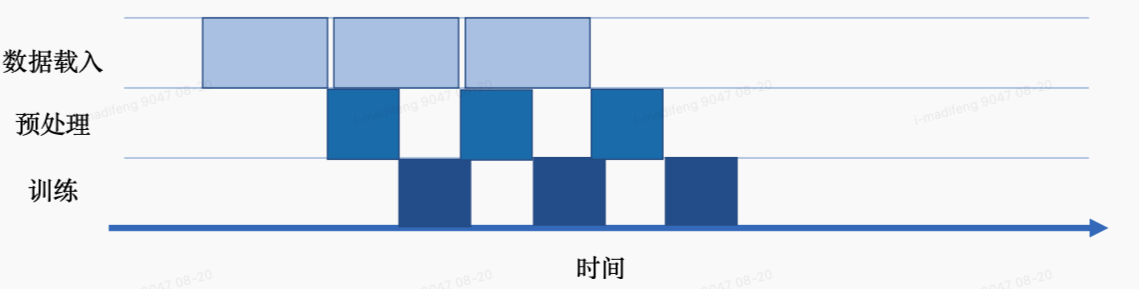
以异步机制来执行计算图训练时,在迭代训练中,当数据通道载入数据后交给后续的数据预处理环节后,不需要等待计算图训练迭代完成,直接读取下一批次的数据。异步机制的引入减少了数据载入、数据预处理、网络训练三个环节的空闲等待时间,能够大幅度缩短迭代训练的整体时间,提高任务执行效率。
参考文献
【1】 机器学习系统——计算图