RAG概述
RAG概述——原理和实现
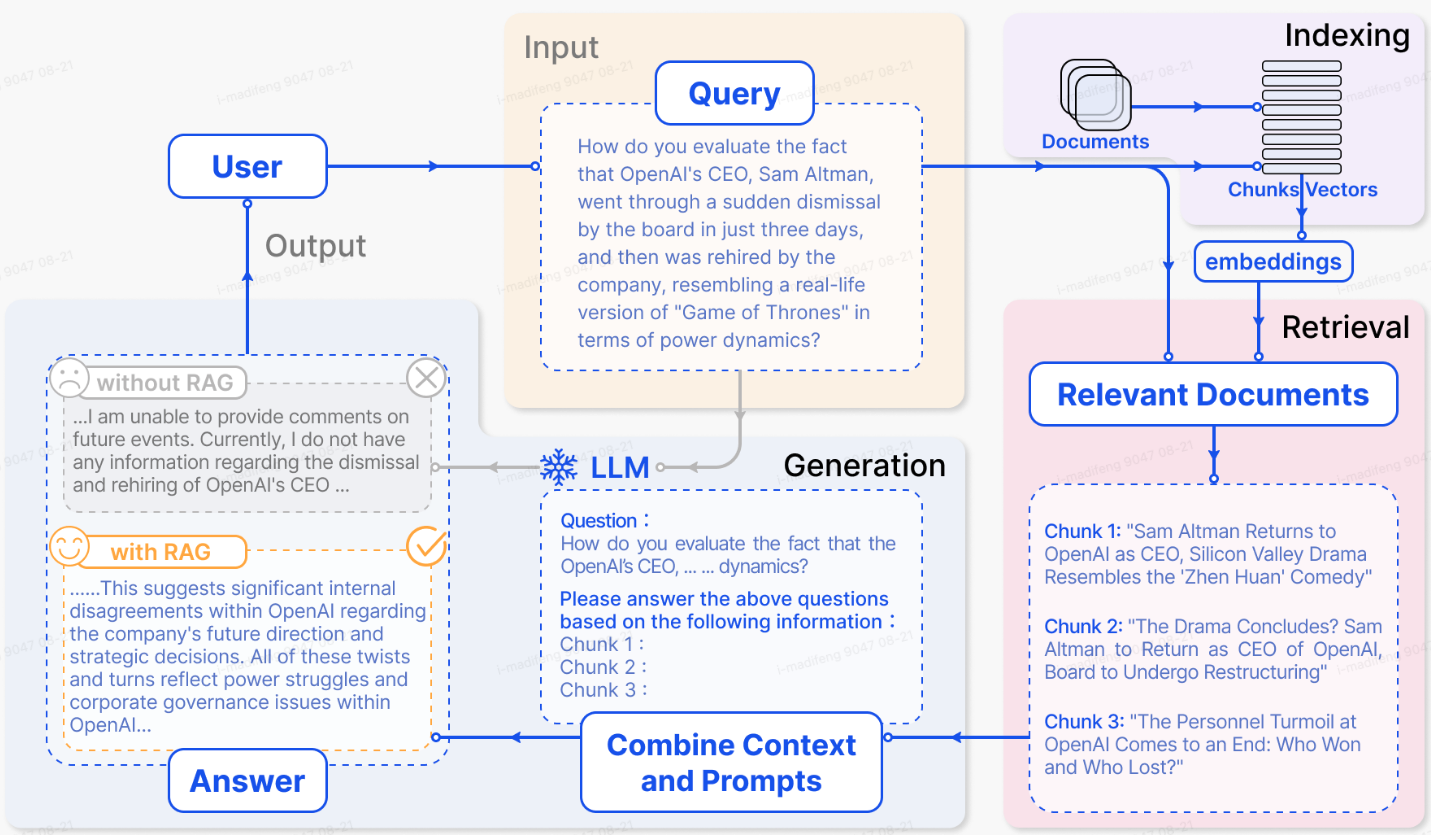
检索-增强生成(Retrieval-Augmented Generation,RAG)是大语言模型中的一种常用的手段,它通过纳入外部知识来增强llm的性能,可以有效避免其出现幻觉并提高答案的准确度。
Problems of llm
大语言模型(LLMs)在自然语言处理尤其是生成上取得了巨大的成就,但它们仍然面临着很大的局限性,特别是在特定领域或知识密集型任务中。在处理超出其训练数据或需要当前信息的查询时,会产生 "幻觉"。
所谓幻觉也就是:大语言模型会给出一些看起来正确但却与事实完全不相符的答案,一个典型的例子就是一本正经地解释“林黛玉倒拔垂杨柳”。这是因为llms事先并不知道水浒传和红楼梦的故事,倘若有一种方法能够将这样的外部知识告诉给模型,模型就可以正确地进行回复。RAG就是通过语义相似性计算从外部知识库中检索相关文档块,从而增强了 LLM。通过引用外部知识,RAG 可有效减少生成与事实不符内容的问题。
How does RAG work?
随着对RAG技术的深入研究,一共出现了三种RAG范式: Naive RAG, Advanced
RAG, and Modular RAG. 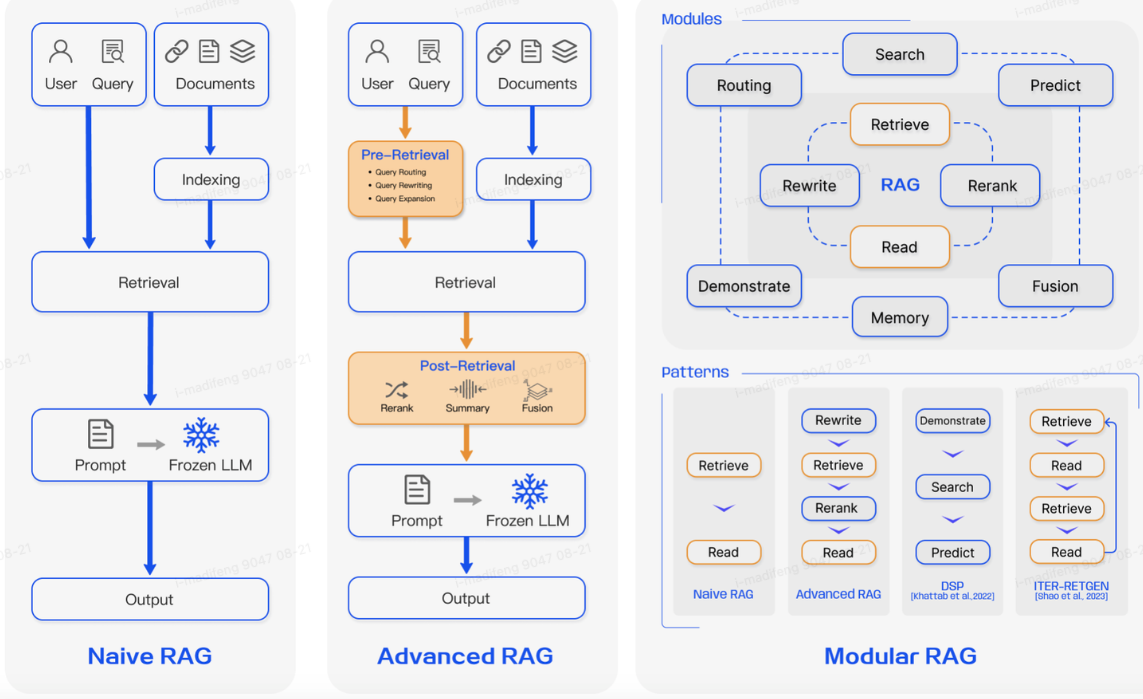
naive rag
indroduce
朴素RAG的基本流程是
索引:对于外部数据,首先要进行清理和对不同格式的提取,然后将其转换为统一的纯文本格式。为了适应语言模型的上下文限制,文本被分割成更小的、易于消化的块。然后,使用嵌入模型将语块编码为矢量表示,并存储到矢量数据库中。这一步骤对于在随后的检索阶段进行高效的相似性搜索至关重要。
检索:收到用户查询后,RAG 系统会使用索引编制阶段使用的相同编码模型,将查询转换为矢量表示。然后,系统会计算查询向量与索引语料库中的语块向量之间的相似度得分。系统会优先检索与查询相似度最高的 K 个语块。将检索到的数据与用户查询一起作为输入传递给语言模型。
生成:提出的查询和选定的文档被合成为一个连贯的提示(一般会有各类模板),而大型语言模型的任务就是对此作出回应。该模型的回答方法可根据任务的具体标准而有所不同,使其既能利用固有的参数知识,也能根据所提供文档中包含的信息进行回答。在持续对话的情况下,任何现有的对话历史记录都可以整合到提示中,从而使模型能够有效地参与多轮对话互动。
这是一种最早也最基本的RAG技术,简单来说就是,它遵循的传统流程是将文档索引到矢量数据库中,根据与用户查询的相似度检索最相关的语块,然后将查询和检索到的语块一起输入语言模型以生成最终答案。
drawbacks
主要是三个问题:
- 检索阶段往往在精确度和召回率方面存在困难,导致选择错位或不相关的信息块,以及丢失关键信息。
- 在生成回复时,模型可能会面临幻觉问题,即生成的内容与检索到的上下文不符。这一阶段还可能出现输出内容不相关、有误或有偏差的情况,从而影响回复的质量和可靠性。
- 将检索到的信息与不同的任务进行整合有时会导致输出结果脱节或不连贯。当从多个来源检索到类似信息时,这一过程还可能遇到冗余问题,从而导致重复的回复。确定不同段落的意义和相关性,并确保文体和音调的一致性,这些都增加了工作的复杂性。
可以看到面对复杂的问题,基于原始查询的单一检索可能不足以获取足够的上下文信息。此外,生成模型可能会过度依赖增强信息,导致输出结果只是重复检索到的内容,而没有增加有见地的或综合的信息。
advanced rag
高级 RAG 为了提高检索质量,它采用了检索前和检索后策略。还通过使用滑动窗口方法、细粒度分割和元数据的整合,改进了索引技术。
预检索过程。这一阶段的主要重点是优化索引结构和原始查询。优化索引的目标是 提高索引内容的质量 。这涉及以下策略:提高数据粒度、优化索引结构、添加元数据、优化排列和混合检索。而查询优化的目标是 使用户的原始问题更清晰、更适合检索任务。常见的方法包括查询重写查询转换、查询扩展等技术。
例如:将问题"what's the French capital?"更换为"What is the capital city of France?"
检索后过程。检索到相关上下文后,将其与查询进行有效整合至关重要。检索后流程的主要方法包括重新排序信息块和压缩上下文。对检索到的信息重新排序,将最相关的内容移至提示边缘是一项关键策略。将所有相关文档直接输入 LLM 可能会导致信息过载(即用不相关的内容冲淡对关键细节的关注)。为了减轻这种情况,检索后的工作主要集中在选择基本信息、强调关键部分以及缩短要处理的上下文。
modular rag
模块化 RAG 架构具有更强的适应性和多功能性,它采用了多种策略来改进其组件,例如为相似性搜索添加搜索模块,以及通过微调完善检索器。
新模块:模块化 RAG 框架引入了额外的专业组件,以增强检索和处理能力。
- 搜索模块可适应特定场景,使用 LLM 生成的代码和查询语言,在搜索引擎、数据库和知识图谱等各种数据源中进行直接搜索。
- 内存模块利用 LLM 的内存引导检索,创建了一个无限制的内存池,通过迭代式自我增强,使文本与数据分布更紧密地结合在一起。
- 预测模块旨在通过 LLM 直接生成上下文,确保相关性和准确性,从而减少冗余和噪音。
- "任务适配器"(Task Adapter)模块可根据各种下游任务对 RAG 进行量身定制,自动对zero-shot input进行及时检索,并通过few-shot查询生成创建特定任务检索器。这种综合方法不仅简化了检索流程,还显著提高了检索信息的质量和相关性,以更高的精度和灵活性满足各种任务和查询的需要。
新模式:模块化 RAG 允许模块替换或重新配置,以应对特定挑战,因而具有出色的适应性。此外,模块化 RAG 还通过集成新模块或调整现有模块之间的交互流程来扩展这种灵活性,从而增强其在不同任务中的适用性。
comparison between ft and rag
- RAG 可以比作为模型提供量身定做的信息检索教科书,是精确信息检索任务的理想选择。相比之下,FT 就好比学生随着时间的推移不断内化知识,适用于需要复制特定结构、风格或格式的场景。
- RAG 在动态环境中表现出色,可提供实时知识更新并有效利用外部知识源,具有很高的可解释性。不过,它的延迟较高,而且在数据检索方面需要考虑道德问题。另一方面,FT 更为静态,更新时需要重新训练,但可以对模型的行为和风格进行深度定制。它需要大量的计算资源来准备和训练数据集,虽然可以减少幻觉,但在处理不熟悉的数据时可能会面临挑战。
- 在 RAG 和 FT 之间做出选择,取决于应用环境中对数据动态、定制和计算能力的具体需求。RAG 和 FT 并不相互排斥,可以相互补充,在不同层面上增强模型的能力。
Pratical
项目地址:a simple local rag
这个项目介绍了如何建立 一个RAG 管道,使我们能够与llm聊天,并且llm能够学到pdf文档中的知识。
通过编写以下代码
- 打开 PDF 文档(几乎可以使用任何 PDF 文档)。
- 将 PDF 教科书的文本格式化,为嵌入模型做好准备(这一过程称为文本分割/分块)。
- 嵌入教科书中的所有文本块,并将其转化为我们可以存储的数字表示。
- 建立一个检索系统,使用矢量搜索根据查询找到相关的文本块。
- 创建一个包含检索到的文本片段的提示。
- 根据教科书中的段落生成查询答案。
- 上述步骤可分为两个主要部分:
- 文档预处理/嵌入创建(步骤 1-3)。
- 搜索和回答(第 4-6 步)。
参考文献
【1】Three Paradigms of Retrieval-Augmented Generation (RAG) for LLMs
【2】Retrieval-Augmented Generation for Large Language Models: A Survey https://arxiv.org/pdf/2312.10997