Grafana Loki 介绍和使用
Grafana Loki 介绍和使用
Grafana
Grafana 是一个开源的可视化和监控工具,广泛用于分析和展示时间序列数据(如系统性能指标、应用程序日志和业务数据)。它提供了强大的数据可视化功能,支持多种数据源,并能够通过动态仪表板展示各种实时监控信息。Grafana 常用于运维监控、DevOps、IoT、云计算等领域。 ### 特性 Grafana 能与多种不同类型的数据源集成,包括 Prometheus、InfluxDB、Elasticsearch、MySQL、PostgreSQL、Graphite 等。这意味着用户可以采集不同的数据存储在不同的数据库中,并且能够通过grafana将其集成在一起共同展示。每种数据源都有独特的查询语言,Grafana 提供灵活的查询编辑器来帮助用户构建查询语句,适配不同的数据源。
Grafana 提供了可高度定制化的 仪表板(Dashboard),用户可以通过多种可视化组件(如折线图、柱状图、热力图、表格等)来显示数据。仪表板支持动态交互,如缩放、过滤、实时刷新等,便于监控时间序列数据的变化。仪表板可以共享或通过 API 自动生成,方便团队协作和自动化管理。
Grafana 具备 告警功能,允许用户设定告警规则。当监控的某些指标超过预设阈值时,Grafana 可以通过电子邮件、Slack、PagerDuty 等方式发送通知。告警系统与仪表板集成,可以直接在图表上显示告警状态,帮助用户快速发现异常。
Grafana 提供细粒度的用户权限管理,支持多租户系统。你可以为不同用户或团队分配不同的访问权限,限制他们对仪表板和数据源的访问。支持与外部身份验证系统集成(如 OAuth、LDAP),简化用户管理。
Grafana 拥有丰富的插件生态,用户可以通过插件扩展其功能,如添加新的数据源、可视化组件或面板。官方插件库和社区插件库中有大量免费的插件可供使用。支持 JSON 和 CSV 等格式的数据,可以通过插件导入或导出数据。
kubernetes
Kubernetes(简称 K8s)是一个开源的容器编排平台,用于自动化应用容器的部署、扩展和管理。Kubernetes 的核心目标是帮助用户管理和调度大量容器化应用,使应用能够在多个机器或云环境中平稳运行。
Kubernetes 的核心概念:
- 节点(Node):Kubernetes
集群中的每台物理或虚拟机,称为节点。每个节点都运行容器化的应用,并由集群中的主节点(Master)进行管理。
- Pod:Kubernetes 中最小的部署单元,一个 Pod
是一组紧密耦合的容器,通常运行在同一台主机上,共享网络和存储。 -
Service:Kubernetes 中的 Service
是一种抽象层,用于将一组 Pod 的网络服务暴露给其他应用或用户,无论这些
Pod 是否被销毁或重建。 - Deployment:Deployment
是定义和管理应用的声明性配置,Kubernetes 会根据 Deployment
设定的规则自动确保应用的状态与期望一致(如应用的副本数量、版本升级等)。
- Namespace:Namespace
用于对集群内的资源进行分组,使不同的团队或项目能够共享同一个 Kubernetes
集群而不会产生冲突。 - ConfigMap 和 Secret:ConfigMap
用于存储应用的非敏感配置信息,Secret 则用于存储敏感数据(如密码、API
密钥等),并可以安全地提供给 Pod。 -
Volumes:用于持久化存储,Kubernetes 支持将外部存储(如
NFS、云存储)挂载到 Pod 中的容器。
另一方面,Pod 是 Kubernetes 中的基本计算单元,而服务器集群(即 Kubernetes 集群)是一个管理这些 Pod 的基础设施环境。它们的关系如下:
Kubernetes 集群:
• 服务器集群 是 Kubernetes 运行 Pod 的物理或虚拟服务器的集合。在 Kubernetes 中,这些服务器被称为 节点(Nodes)。 • 一个 Kubernetes 集群包含多个节点,每个节点都是一台物理机或虚拟机,负责运行 Pod,并执行调度、网络和存储任务。
节点 (Node):
• 每个节点都包含一个 Kubelet(负责与 Kubernetes 控制面板通信的代理),以及一个容器运行时(如 Docker 或 containerd),用于实际执行 Pod 内的容器。 • 节点的主要作用是为 Pod 提供计算资源,包括 CPU、内存、网络和存储等。
Pod 的调度与运行:
• 当在 Kubernetes 中创建一个 Pod 时,Kubernetes 控制面板(Control Plane) 会将 Pod 调度到集群中的某个节点上运行。 • 调度过程会根据集群中节点的资源使用情况和调度策略,自动选择一个最合适的节点来运行 Pod。 • 一旦 Pod 被分配到某个节点,节点中的容器运行时会启动 Pod 中的容器,并为其分配资源。
Pod 与服务器集群的关系:
• Pod 是运行在集群节点上的逻辑单元。一个 Pod 必须运行在某个具体的节点(即服务器)上。 • 集群管理多个 Pod 的分布和状态。Kubernetes 确保 Pod 在集群中能够均匀分布,充分利用节点资源,并且会根据需要(例如节点故障或负载变化)动态调度和重新启动 Pod。 • Pod 是集群的工作负载。在集群中,Pod 代表应用或服务的实例,它们运行在节点上,集群负责管理这些 Pod 的生命周期、可用性和扩展。
loki
Grafana Loki 是一组开源组件,可以组合成功能齐全的日志记录堆栈。小索引和高度压缩块的设计简化了操作并显着降低了 Loki 的成本。与其他日志系统不同,Loki 的构建理念是仅对有关日志标签的元数据进行索引(就像 Prometheus 标签一样)。然后,日志数据本身会被压缩并以块的形式存储在 Amazon Simple Storage Service (S3) 或 Google Cloud Storage (GCS) 等对象存储中,甚至存储在本地文件系统上。
Loki 是由 Grafana Labs 开发的、针对 Kubernetes 环境优化的日志聚合系统,但它可以运行在多种不同的环境中。
Kubernetes 是 Loki 最常用的部署环境。Loki 可以与 Prometheus 和 Grafana 无缝集成,监控 Kubernetes 集群中的容器日志。Loki 在 Kubernetes 中通过 Helm Chart 进行部署,通常与 Promtail(日志收集器)一起使用,用于抓取 Pod 的日志。
使用流程
 - 一般会使用 Helm
Chart,以简单可扩展模式在 Kubernetes 上安装 Loki。
- 一般会使用 Helm
Chart,以简单可扩展模式在 Kubernetes 上安装 Loki。
- 接下来部署 Grafana 代理以从您的应用程序收集日志。
- 在 Kubernetes 上,使用 Helm Chart部署 Grafana 代理。配置 Grafana Agent 以从 Kubernetes 集群中抓取日志,并添加 Loki 端点详细信息。
- 为日志添加标签。例如添加描述日志来源的标签(区域、集群、环境等)。
- 然后部署 Grafana 或 Grafana Cloud 并配置 Loki 数据源。
- 最后在 Grafana 主菜单中选择“Explore”功能。
- 选择一个时间范围。
- 选择 Loki 数据源。
- 在查询编辑器中使用 LogQL,使用生成器视图探索标签,或使用“启动查询”按钮从示例预配置查询中进行选择。
tips: 日志流是一组共享相同标签的日志。标签可帮助 Loki 在数据存储中查找日志流,因此拥有一组高质量的标签是高效执行查询的关键。 ### 实际例子 如果想试验 Loki,官方提供了一个dockerfile,可以使用 Loki 附带的 Docker Compose 文件在本地运行 Loki。它以整体部署模式运行 Loki,并包含一个用于生成日志的示例应用程序。
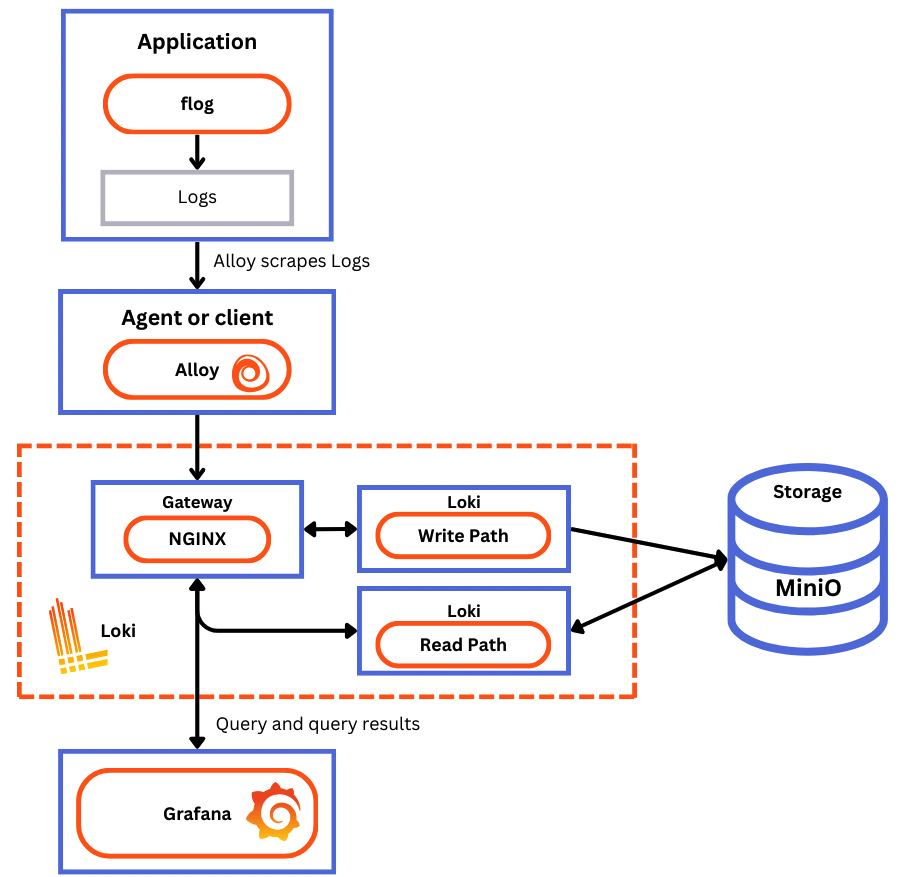 Docker Compose 配置运行以下组件,每个组件都在自己的容器中:
Docker Compose 配置运行以下组件,每个组件都在自己的容器中:
flog:生成日志行。 flog 是常见日志格式的日志生成器。
Grafana Alloy:从 flog 上刮削flog,然后通过网关将它们推送给 Loki。
网关 (nginx),接收请求并根据请求的 URL 将它们重定向到适当的容器。
Loki 读取组件:运行查询前端和query。
Loki 写入组件:运行distributor和接收器。
Loki 后端组件:运行 Index Gateway、Compactor、Ruler、Bloom Compactor(实验性)和 Bloom Gateway(实验性)。
Minio:Loki 用它来存储索引和块。
Grafana:提供 Loki 中captures的日志行的可视化
具体请参考:quickstart
Details
Grafana Loki
有两种主要的文件类型:索引(index)和块(chunks):
- index是在哪里查找特定标签集的日志的目录。 -
chunks是一组特定标签的日志条目的容器。

Index format
目前支持两种索引格式作为带有index shipper的单个存储格式:
TSDB(推荐) 时间序列数据库(或简称 TSDB)是最初由 Prometheus 维护者为时间序列(度量)数据开发的索引格式。它是可扩展的,并且比已弃用的 BoltDB 索引具有许多优点。 Loki 中的新存储功能仅在使用 TSDB 时可用。
Bolt 是用 Go 编写的低级事务性键值存储。
Chunks format
块是特定时间范围的流(唯一的标签集)的日志行的容器。
下面的 ASCII 图详细描述了块格式: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37----------------------------------------------------------------------------
| | | |
| MagicNumber(4b) | version(1b) | encoding (1b) |
| | | |
----------------------------------------------------------------------------
| #structuredMetadata (uvarint) |
----------------------------------------------------------------------------
| len(label-1) (uvarint) | label-1 (bytes) |
----------------------------------------------------------------------------
| len(label-2) (uvarint) | label-2 (bytes) |
----------------------------------------------------------------------------
| len(label-n) (uvarint) | label-n (bytes) |
----------------------------------------------------------------------------
| checksum(from #structuredMetadata) |
----------------------------------------------------------------------------
| block-1 bytes | checksum (4b) |
----------------------------------------------------------------------------
| block-2 bytes | checksum (4b) |
----------------------------------------------------------------------------
| block-n bytes | checksum (4b) |
----------------------------------------------------------------------------
| #blocks (uvarint) |
----------------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
----------------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
----------------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
----------------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
----------------------------------------------------------------------------
| checksum(from #blocks) |
----------------------------------------------------------------------------
| #structuredMetadata len (uvarint) | #structuredMetadata offset (uvarint) |
----------------------------------------------------------------------------
| #blocks len (uvarint) | #blocks offset (uvarint) |
----------------------------------------------------------------------------
mint 和 maxt 分别描述最小和最大 Unix 纳秒时间戳。
StructuredMetadata 部分存储不重复的字符串。它用于存储结构化元数据中的标签名称和标签值。注意,结构化元数据部分中的标签字符串和长度是压缩存储的。Block format
一个block由一系列条目组成,每个条目都是一个单独的日志行。请注意,块的字节是压缩存储的。以下是未压缩时的形式:
1
2
3
4
5
6
7
8
9-----------------------------------------------------------------------------------------------------------------------------------------------
| ts (varint) | len (uvarint) | log-1 bytes | len(from #symbols) | #symbols (uvarint) | symbol-1 (uvarint) | symbol-n*2 (uvarint) |
-----------------------------------------------------------------------------------------------------------------------------------------------
| ts (varint) | len (uvarint) | log-2 bytes | len(from #symbols) | #symbols (uvarint) | symbol-1 (uvarint) | symbol-n*2 (uvarint) |
-----------------------------------------------------------------------------------------------------------------------------------------------
| ts (varint) | len (uvarint) | log-3 bytes | len(from #symbols) | #symbols (uvarint) | symbol-1 (uvarint) | symbol-n*2 (uvarint) |
-----------------------------------------------------------------------------------------------------------------------------------------------
| ts (varint) | len (uvarint) | log-n bytes | len(from #symbols) | #symbols (uvarint) | symbol-1 (uvarint) | symbol-n*2 (uvarint) |
-----------------------------------------------------------------------------------------------------------------------------------------------
ts 是日志的 Unix 纳秒时间戳,而 len 是日志条目的长度(以字节为单位)。符号存储对包含块的structedMetadata中的标签名称和值的实际字符串的引用。
Write and Read
写入路径 从较高层面来看,Loki 中的写入路径的工作原理如下:
- distributor接收带有流和日志行的 HTTP POST 请求。
- distributor对请求中包含的每个流进行哈希处理,以便它可以根据一致哈希环中的信息确定需要将其发送到的Ingester实例。
- distributor将每个流发送到适当的Ingester及其副本(基于配置的复制因子)。
- Ingester接收带有日志行的流,并为流的数据创建一个块或附加到现有块。每个租户和每个标签集的块都是唯一的。
- Ingester确认写入。
- Distributor等待大多数(法定人数)Ingester确认他们的写入。
- 如果distributor至少收到法定数量的已确认写入,则它会以成功响应(2xx 状态代码)。或者在写入操作失败时出现错误(4xx 或 5xx 状态代码)。
读取路径 概括地说,Loki 中的读取路径的工作原理如下:
- 查询前端接收带有 LogQL 查询的 HTTP GET 请求。
- 查询前端将查询拆分为子查询并将它们传递给查询调度程序。
- query从调度器中提取子查询。
- query将查询传递给内存数据的所有Ingester。
- Ingester返回与查询匹配的内存中数据(如果有)。
- 如果Ingester未返回数据或返回的数据不足,则query会延迟从后备存储加载数据并对其运行查询。
- query迭代所有接收到的数据并进行重复数据删除,将子查询的结果返回到查询前端。
- 查询前端等待查询的所有子查询完成并由query返回。
- 查询前端将各个结果合并为最终结果并将其返回给客户端。
Distributor:
Distributor
Service负责处理来自客户端的传入推送请求。这是日志数据写入路径的第一步。一旦Distributor收到
HTTP
请求中的一组流,就会验证每个流的正确性并确保其在配置的租户(或全局)限制内。然后,每个有效流会并行发送到
n 个Ingester,其中 n 是数据的replication
factor。Distributor使用一致性哈希来确定将流发送到的接收器。
Ingester:
Ingester Service 负责持久化数据并将其传送到写入路径上的长期存储(Amazon
Simple Storage Service、Google Cloud Storage、Azure Blob Storage
等),并返回最近摄取的in-memory日志数据以供查询在读取路径上。
Ingesters 包含一个生命周期管理器,用于管理哈希环中 Ingesters 的生命周期。每个摄取器的状态为 PENDING、JOINING、ACTIVE、LEAVING 或 UNHEALTHY:
PENDING 是 Ingester 等待另一个正在LEAVING的 Ingester 进行切换时的状态。
JOINING 是 Ingester 当前将其令牌插入环并初始化自身时的状态。它可能会接收对其拥有的令牌的写入请求。
ACTIVE 是 Ingester 完全初始化时的状态。它可以接收对其拥有的令牌的写入和读取请求。
LEAVING 是 Ingester 关闭时的状态。它可能会接收对其内存中仍具有的数据的读取请求。
UNHEALTHY 是 Ingester 心跳失败时的状态。 UNHEALTHY 由distributor在定期检查环时设置。
Ingester接收到的每个日志流都会在内存中构建成一组许多“块”,并以可配置的时间间隔刷新到后备存储后端。
如果Ingester进程崩溃或突然退出,所有尚未刷新的数据都将丢失。 Loki 通常配置为复制每个日志的多个副本(通常是 3 个)以减轻这种风险。
当持久存储提供者发生刷新时,块会根据其租户、标签和内容进行哈希处理。这意味着具有相同数据副本的多个摄取器不会将相同的数据写入后备存储两次,但如果其中一个副本的任何写入失败,则将在后备存储中创建多个不同的块对象。请参阅查询器了解如何进行重复数据删除。
Replication factor:
为了减少在任何单个Ingester上丢失数据的可能性,distributor会将写入数据转发给其中的复制因子。通常,复制因子为
3。复制允许Ingester重新启动和退出,而不会导致写入失败,并在某些情况下增加了防止数据丢失的额外保护。
从广义上讲,对于推送给disttibutor的每个标签集(称为流),Distributor都会对标签进行散列处理,并使用得到的值在环中查找复制因子Ingester(这是一个公开分布式散列表的子组件)。然后,它会尝试把相同的数据写入到所有的接收器中。如果成功写入的数据少于quorum,就会产生错误。quorum的定义是 floor( replication_factor / 2 ) + 1。因此,对于我们的复制因子 3,我们要求有两次写入成功。如果成功写入的次数少于两次,分发器就会返回错误,写入操作将被重试。
Hashing:
distributor使用一致的哈希算法和可配置的复制因子来确定哪些Ingester服务实例应接收给定的数据流。
数据流是一组与租户和唯一标签集相关联的日志。使用租户 ID 和标签集对数据流进行散列,然后使用散列找到要将数据流发送给的Ingester。
哈希环通过使用成员列表协议的点对点通信进行维护,或存储在密钥-值存储(如 Consul)中,用于实现一致的哈希;所有Ingester都用自己拥有的一组令牌将自己注册到哈希环中。每个令牌都是一个随机的无符号 32 位数。除了一组令牌,Ingester还会将自己的状态注册到哈希环中。状态 “JOINING ”和 “ACTIVE ”都会收到写入请求,而 “ACTIVE ”和 “LEAVING ”则会收到读取请求。在进行哈希查找时,Distributor只使用处于相应状态的Ingester的令牌。
要进行哈希值查询,Distributor要找到其值大于流哈希值的最小适当标记。当复制因子大于 1 时,属于不同Ingester的下一个令牌(顺时针环形)也将包含在结果中。
这种哈希值设置的效果是,Ingester拥有的每个标记都负责一定范围的哈希值。如果存在值为 0、25 和 50 的三个令牌,则将向拥有令牌 25 的Ingester提供哈希值 3;拥有令牌 25 的摄取者负责 1-25 的哈希范围。
Log queries
所有 LogQL 查询都包含日志流选择器。

日志流选择器后面可以跟一个日志pipeline。日志pipeline是一组链接在一起并应用于所选日志流的阶段表达式。每个表达式都可以过滤、解析或改变日志行及其各自的标签。
1
{container="query-frontend",namespace="loki-dev"} |= "metrics.go" | logfmt | duration > 10s and throughput_mb < 500{container="query-frontend",namespace="loki-dev"}
,其目标是 loki-dev 命名空间中的 query-frontend 容器。 - 日志pipeline
|= "metrics.go" |logfmt |duration > 10s and throughput_mb < 500,这将过滤掉包含单词metrics.go的日志,然后解析每个日志行以提取更多标签并使用它们进行过滤。
为了避免转义特殊字符,在引用字符串时可以使用 `(反引号) 而不是 "。例如,`\w+` 与 "\\w+" 相同。这在编写包含多个反斜杠的正则表达式时特别有用。log selector
日志流选择器确定查询结果中包含哪些日志流。日志流是日志内容的唯一来源,例如文件。然后,更细粒度的日志流选择器将搜索流的数量减少到可管理的数量。这意味着传递给日志流选择器的标签将影响查询执行的相对性能。
日志流选择器由一个或多个以逗号分隔的键值对指定。每个键都是一个日志标签,每个值都是该标签的值。大括号({
和 })分隔流选择器。 1
{app="mysql",name="mysql-backup"}
适用于 Prometheus 标签选择器的相同规则也适用于 Grafana Loki
日志流选择器。标签名称后面的 =
运算符是标签匹配运算符。支持以下标签匹配运算符: 1
2
3
4
5=:完全相等
!=: 不等于
=~: 正则表达式匹配
!~: 正则表达式不匹配
正则表达式日志流示例:1
2
3{name =~ “mysql.+”}
{name !~ “mysql.+”}
{name !~ `mysql-\d+`}(?s)search_term.+匹配
search_term\n。或者,您可以将\s(匹配空格,包括换行符)与
\S(匹配非空格字符)结合使用来匹配所有字符,包括换行符。
正则表达式日志流换行符: 1
2
3{name =~ ".*mysql.*"}: 与带有换行符的日志标签值不匹配
{name =~ "(?s).*mysql.*}:将日志标签值与换行符匹配
{name =~ "[\S\s]*mysql[\S\s]*}:将日志标签值与换行符匹配
log pipeline
日志pipeline可以附加到日志流选择器以进一步处理和过滤日志流。它由一组表达式组成。对于每个日志行,每个表达式都按从左到右的顺序执行。如果表达式过滤掉日志行,pipeline将停止处理当前日志行并开始处理下一个日志行。
某些表达式可以改变日志内容和相应的标签,然后可用于后续表达式中的进一步过滤和处理。例如:
日志pipeline表达式属于以下四类之一:
- 过滤表达式:行过滤表达式和标签过滤表达式
- 解析表达式
- 格式化表达式:行格式表达式和标签格式表达式
- 标签表达式:删除标签表达式并保留标签表达式
line filter expression
line filter expression对来自匹配日志流的聚合日志执行分布式
grep。它搜索日志行的内容,丢弃那些与区分大小写的表达式不匹配的行。
每个line filter
expression都有一个过滤运算符,后跟文本或正则表达式。支持这些过滤器运算符:
1
2
3
4|=:日志行包含字符串
!=: 日志行不包含字符串
|~:日志行包含正则表达式的匹配项
!~: 日志行不包含正则表达式的匹配项|~和
!~ 正则表达式运算符不是完全锚定的。这意味着
.正则表达式字符匹配所有字符,包括换行符。
例子:
保留包含子字符串“error”的日志行: 1
|=“error”1
{job=“mysql”} |=“error”
丢弃具有子字符串“kafka.server:type=ReplicaManager”的日志行:
1
!= "kafka.server:type=ReplicaManager"1
{instance=~"kafka-[23]",name="kafka"} != "kafka.server:type=ReplicaManager"tsdb-ops 开头并以 io:2003
结尾的子字符串的日志行。使用正则表达式的完整查询: 1
{name="kafka"} |~ "tsdb-ops.*io:2003"error=开头且后跟 1
个或多个单词字符的子字符串的日志行。使用正则表达式的完整查询:
1
{name="cassandra"} |~ `error=\w+`
label filter expression
标签过滤表达式允许使用原始标签和提取的标签来过滤日志行。它可以包含多个谓词。
谓词包含标签标识符、操作和用于与标签进行比较的值。
例如,对于
cluster="namespace",cluster是标签标识符,操作是=,值为“namespace”。标签标识符始终位于操作的左侧。
loki支持从查询输入自动推断出的多种值类型。
- String使用双引号或反引号,例如“200”或“us-central1”。
- Duration是十进制数字序列,每个数字都有可选的分数和单位后缀,例如“300ms”、“1.5h”或“2h45m”。有效的时间单位为“ns”、“us”(或“μs”)、“ms”、“s”、“m”、“h”。
- Number 为浮点数(64 位),如 250、89.923。
- Byte是十进制数字序列,每个数字都有可选的分数和单位后缀,例如“42MB”、“1.5Kib”或“20b”。有效字节单位为“b”、“kib”、“kb”、“mib”、“mb”、“gib”、“gb”、“tib”、“tb”、“pib”、“pb”、“eib” ”,“eb”。
使用duration、number和byte将在比较之前转换标签值并支持以下比较器:
==或=表示相等。!=表示不等式。>和>=表示大于和大于或等于。<和<=表示小于和小于或等于。 例如,logfmt |duration > 1m且bytes_consumed > 20MB
如果标签值转换失败,则不会过滤日志行并添加 __error__ 标签。可以使用 and 和 or 链接多个谓词,它们分别表示 and 和 or 二元运算。并且可以用逗号、空格或其他pipeline等效地表示。标签过滤器可以放置在log pipeline中的任何位置。
这意味着以下所有表达式都是等效的: 1
2
3
4| duration >= 20ms or size == 20kb and method!~"2.."
| duration >= 20ms or size == 20kb | method!~"2.."
| duration >= 20ms or size == 20kb , method!~"2.."
| duration >= 20ms or size == 20kb method!~"2.."
这些示例是等效的: 1
2| duration >= 20ms or method="GET" and size <= 20KB
| ((duration >= 20ms or method="GET") and size <= 20KB)
Parser expression
解析器表达式可以从日志内容中解析并提取标签。然后,这些提取的标签可用于使用标签过滤器表达式进行过滤或用于度量聚合。
提取的标签键会被所有解析器自动清理,以遵循 Prometheus 指标名称约定。(它们只能包含 ASCII 字母和数字,以及下划线和冒号。它们不能以数字开头。)
例如,pipeline | json 将生成以下映射: 1
{ "a.b": {c: "d"}, e: "f" }1
{a_b_c="d", e="f"}
如果出现错误,例如,如果该行不是预期的格式,则日志行不会被过滤,而是会添加一个新的 error 标签。
如果原始日志流中已存在提取的标签键名称,则会在提取的标签键后面加上 _extracted 关键字作为后缀,以区分两个标签。可以使用标签格式化程序表达式强制覆盖原始标签。
如果可以的话,使用预定义的解析器 json 和 logfmt 会更容易。如果不能,模式和正则表达式解析器可用于具有不寻常结构的日志行。模式解析器编写起来更容易、更快;它的性能也优于正则表达式解析器。单个日志管道可以使用多个解析器。这对于解析复杂的日志很有用。
Pattern
模式解析器允许通过定义模式表达式(|pattern “<pattern-expression>”)从日志行中显式提取字段。该表达式与日志行的结构匹配。
例如: 1
0.191.12.2 - - [10/Jun/2021:09:14:29 +0000] "GET /api/plugins/versioncheck HTTP/1.1" 200 2 "-" "Go-http-client/2.0" "13.76.247.102, 34.120.177.193" "TLSv1.2" "US" ""1
<ip> - - <_>“<method><uri><_>”<status><size><_>“<agent>”<_>1
2
3
4
5
6"ip" => "0.191.12.2"
"method" => "GET"
"uri" => "/api/plugins/versioncheck"
"status" => "200"
"size" => "2"
"agent" => "Go-http-client/2.0"
pattern expression由captures和literals组成。
captures是由<和>字符分隔的字段名称。
定义字段名称example。未命名的captures显示为<_>。未命名的captures会跳过匹配的内容。
captures从行开头或前一组literals匹配到行结尾或下一组literals。如果captures不匹配,模式解析器将停止。
literals可以是任意 UTF-8 字符序列,包括空白字符。
默认情况下,模式表达式锚定在日志行的开头。如果表达式以literals开头,则日志行也必须以同一组literals开头。如果您不想将表达式锚定在开头,请在表达式的开头使用
<_>。
考虑日志行 1
level=debug ts=2021-06-10T09:24:13.472094048Z caller=logging.go:66 traceID=0568b66ad2d9294c msg="POST /loki/api/v1/push (204) 16.652862ms"msg=,请使用表达式:
1
<_> msg="<method> <path> (<status>) <latency>"
- 它不包含任何命名捕获。
- 它包含两个连续的捕获,未用空格字符分隔。
line format expression
行格式表达式可以使用 文本/模板
格式重写日志行内容。它需要一个字符串参数
| line_format "{{.label_name}}",这是模板格式。所有标签都被注入变量到模板中,并且可以与
{{.label_name}} 一起使用。
例如下面的表达式:
{container=“frontend”}| logfmt | line_format "{{.query}}
{{.duration}}"
将提取并重写日志行以仅包含查询和请求的持续时间。可以在模板中使用双引号字符串或反引号
'{{.label_name}}' 以避免需要转义特殊字符。
line_format 还支持数学函数。例子:
如果我们有以下标签 ip=1.1.1.1、status=200
和duration=3000(ms),我们可以将持续时间除以 1000
以获得以秒为单位的值。
{container="frontend"} |logfmt | line_format "{{.ip}}
{{.status}} {{div .duration 1000}}"
上面的查询将为我们提供 1.1.1.1 200 3的行
Tips:还可以使用 line 函数访问日志行,并使用 timestamp 函数访问时间戳。
label format expression
| label_format表达式可以重命名、修改或添加标签。它采用逗号分隔的相等操作列表作为参数,可以同时启用多个操作。
当两边都是标签标识符时,例如dst=src,该操作会将src标签重命名为dst。
右侧也可以是模板字符串(双引号或反引号),例如
dst="{{.status}} {{.query}}",在这种情况下,dst
标签值将替换为 文本/模板
评估的结果。这是与| line_format相同的模板引擎。这意味着标签可用作变量,并且可以使用相同的函数列表。
在这两种情况下,如果目标标签不存在,则会创建一个新标签。
重命名形式dst=src将在将 src标签重新映射到
dst 标签后删除它。但是,template
format将保留引用的标签,这样
dst="{{.src}}"会导致dst 和
src 具有相同的值。
每个表达式中单个标签名称只能出现一次。这意味着 | label_format foo=bar,foo="new" 是不允许的,但您可以使用两个表达式来达到所需的效果: |label_format foo=bar | label_format foo =“new”