国科大GPU架构与编程25秋大作业二入门指南
GPU大作业入门指南
本教程旨在提供一个基本的入门指南,专门为零基础同学打造的完成大作业二的教程,仅限基础题。
基本要求
首先快速回顾一下大作业二的要求:
- 选择一个赛道:摩尔线程,沐曦科技,并行科技
- 根据教材《Programming Massively Parallel Processors: A Hands-on
Approach》要求的章节生成高质量的问答对.PMPP。
- 基础题:Chap 2,3,4,5,6
- 加分题:Chap 1,2,3,4,5,6,7,13,16,17,20
- 选择一种开源大模型:DeepSeek,Qwen,Llama等
- 选择一个大模型微调框架
- 摩尔线程:Llama-Factory
- 并行科技&沐曦科技:Unsloth
- 模型微调
- 基础题:使用生成的问答对进行低秩矩阵微调(lora),输出标准的大模型文件(huggingface transformers)
- 加分题:RAG,PPO,RLHF,SFT etc. 策略进行模型准确率优化
- 模型推理部署
- 基础题:使用大模型进行推理,输出结果,不必要使用推理引擎部署
- 加分题:使用vllm,SGlang等进行推理部署,并根据硬件架构,使用CUDA,PTX,Triton等编程模型加速推理框架的算子。做一个UI界面,起一个响亮的名字🥹
考核要求 :
- 速度(Tokens/s)
- 给定测试集上的准确率+专家打分
背景介绍
没有AI大模型训练经验基础的同学可能会对上述任务一头雾水,包括什么叫做微调,这堆名词(PPO,Lora,SFT etc.)是什么意思,llama-factory,unsloth等是什么,vllm,sglang等又是什么。
大模型基础知识
我们先快速过一遍大模型的基本原理,首先现代几乎所有大模型都是基于Transformer架构的,关于Transformer的详细介绍可以参考我之前的博客文章Transformer的原理与应用。
原版 Transformer 由 Encoder + Decoder
两部分组成,但现在几乎所有语言大模型都只保留 Decoder-only(仅解码器)
架构,这是 GPT、Qwen、DeepSeek、Llama
等模型共同的基础。这里的原因简单来说是因为所有 LLM
的根本任务都是一样的—— 根据前文预测下一个
token。对于生成任务而言,语言模型的“输入”和“输出”其实都在同一个序列上,Transformer
的 Decoder带有 mask
self-attention(只看前面,不看后面),用户输入一部分内容,模型根据输入继续进行接下来的输出。所以decoder是天然适合这种生成任务的,与之对应如果是翻译或者seq2seq任务,就是encoder更擅长。其实最主要的原因还是因为便宜,Decoder-only
在规模化训练下效果最好、最稳定,继续保留encoder反而会增加多余的训练成本。
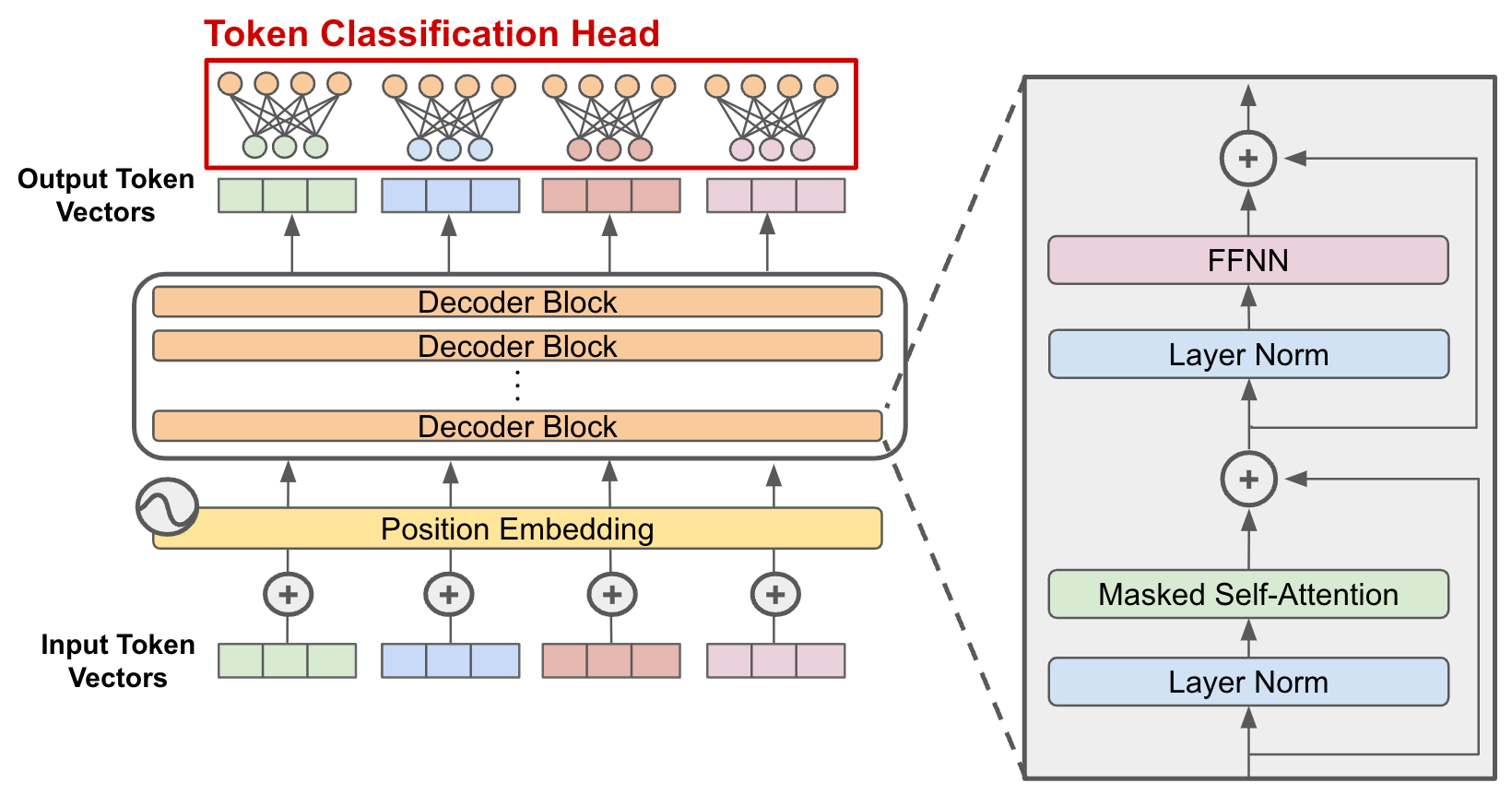
强调这一点是因为让我们大模型的架构有一个最清晰的认识,专注在decoder结构,帮助理解各家大模型的区别到底在哪。
大模型常见的一些参数
Token:Token在大模型中是最基本的文本单元,意味着任何序列都是由这些token组成的。如果学过NLP就知道,这些token并不一定是一个word或者一个字,而是有可能会被拆分为更小的部分。比如说”preview”就会被拆分为”pre”和”view”。为什么不直接用字母呢?如果只有英文训练预料,词表甚至只有26个,但是这样的话模型就很难学到一些长距离的依赖关系,比如说一个字母p后面可能是任何一个其他字母,模型很难学到p后面跟着什么字母的概率。所以词表不能太大,也不能太小。与token最直接相关的关键词就是上下文长度(context),128k,1M等,它们的意思就是词表里有多少个token,也就是输出矩阵的维度。
Embedding:Embedding是token的向量表示,它将token转换为数值向量,这个向量的维度就是embedding的维度,比如768,1024等。Embedding的维度越高,模型的表达能力就越强,但是训练成本也越高,这也就是输入矩阵大小的另一个决定性因素。比如gpt3时的词表大小是50257,嵌入向量的维度是12288.
温度:温度 (Temperature) 控制模型生成内容的随机性和创造性。数值通常在 0 到 1 之间(有些模型可到 2)。
- 低温度 (0.1 - 0.3): 模型变得极度保守、确定。它会每次都选概率最高的那个字。适合:代码生成、数学解题、事实问答。
- 高温度 (0.7 - 1.0): 模型变得活跃、发散。它会尝试选择概率没那么高的字,带来意想不到的组合。适合:写诗、头脑风暴、创意写作。
可以直接验证的是,如果将温度调为0,模型的输出会变得非常确定,那么同一个prompt下,模型的输出都是一样的。
大模型异同
各家大模型都是基于transformer架构,并且还是decoder-only,那为什么能力参差不齐呢?
可以把差异分成三大类:
(1)架构层面.
(2)训练层面(最核心).
(3)推理/工程层面.
架构层面
虽然都是 Decoder-only,但每家在 Transformer Block 里做了一些小改动,例如:
- Attention 机制的不同
- 原始 Attention(GPT-2/GPT-3)
- SwiGLU + Multi-Query Attention(Llama系)
- Grouped-Query Attention (GQA)(大部分新模型)
- 推理更快、KV Cache 更小
- Chunked Attention / Multi-head Latent Attention(DeepSeek)
- 位置编码(Positional Encoding)
- GPT :Learned PE(可学习位置)
- Llama/Qwen:RoPE(旋转位置编码)
- DeepSeek-V3:Dynamic NTK / YaRN
- 激活函数(FFN)
- ReLU(旧时代)
- GeLU(GPT-3)
- SwiGLU / ReGLU(Llama/Qwen/DeepSeek)
- 归一化策略
- RMSNorm(Llama/Qwen/DeepSeek)
- LayerNorm(GPT 系列)
- DeepNorm/PostNorm 变体(Ziya 等)
我们并不需要关心具体是如何实现的,只需要知道各家大模型的架构主要的区别就集中在这几个部件上,还有近来比较热门的Moe模型,也引入了一些新的技术。
训练层面
实际上,真正影响大模型能力的,还是训练层面。这主要体现在各家大模型:
- 用了多少数据
- 用什么 loss,训练目标是什么
- 用什么训练技巧
- 是否做了对齐 RLHF、SFT
比如说不同公司会在 pretrain 时加入:
- next-token prediction(主任务)
- fill-in-the-middle(FIM,Llama 用)
- prefix LM(部分模型)
- masked attention patterns
推理/工程层面
最后就是影响实际体验的部分,同样大小的模型,它们差异可能来自以下优化:
- KV Cache 优化(PagedAttention、FlashAttention-2/3)
- vLLM 推力最大
- DeepSeek-V3 更进一步的 Chunked Attention
- Qwen 2.5 做了 FlashDecoding 优化
- 权重量化技术,量化能力影响 显存需求 × 推理速度,对实际用户影响巨大。
- Llama/Qwen → 非常适配 AWQ/GPTQ/INT8/FP8
- DeepSeek → 特别适配 INT4/FP8 推理
参数量的区别
对于同款架构(通常指基于 Transformer Decoder-only 的架构,如 Llama、GPT 系列)的大模型,参数量的区别主要体现在 “深度”(层数) 和 “宽度”(隐藏层维度) 这两个核心维度的变化上。具体来说,参数量的差异主要体现在以下几个具体的结构参数和权重矩阵上:
核心差异来源:两个关键超参数当一个模型从“小杯”(如 7B)扩展到“超大杯”(如 70B)时,架构逻辑不变,变的是以下两个数值:
- Hidden Size (dmodel):隐藏层维度(宽度)。这是影响最大的因素,因为参数量与它大致呈平方关系。
- Number of Layers (N):Transformer Block 的层数(深度)。参数量与它呈线性关系。
一篇写得很好的计算参数量的文章GPT2参数量计算
模型训练
基于上面部分的介绍,大家已经可以大概选择一个适合的大模型来进行微调。这里有一个有意思的网站可以用来计算模型需要的显存:GPU-poor.
选择了一个模型后,接下来咱们简单介绍一下微调是什么意思。
要知道的是,现在的所有大模型都已经在大量的世界数据上进行了预训练,但是针对具体的场景可能没法涵盖全部的知识。微调(Fine-tuning)是大模型应用的最常见方式,它通过在特定任务上进行训练,让模型能够更好地理解和生成与任务相关的文本。根据微调方式的不同,又可以分为PEFT,FFT,SFT,PPO,DPO等。
- 按照“更新参数的规模”分类可以分为FFT和PEFT等,它们是训练的实现方式
- 按照“任务类型”分类可以分为SFT和RLHF等,它们是训练的具体目标
训练实现方式
全量微调 (Full Fine-Tuning / FFT)
全量微调 (Full Fine-Tuning / FFT)的原理是解冻模型的所有参数,对整个模型的权重进行更新。相当于把整个大脑的知识重新梳理一遍。全量微调的优点是效果上限最高,能彻底改变模型的行为模式。但缺点显而易见就是极度烧钱。需要巨大的显存(通常是模型大小的 3-4 倍以上),还可能出现“灾难性遗忘”(忘了原本通用的知识)。
参数高效微调(Parameter-Efficient Fine-Tuning)
参数高效微调(Parameter-Efficient Fine-Tuning) 的原理是冻结住大模型原本的参数(不改动),只在旁边“外挂”一些小型的参数模块来训练。
核心技术包括:
Adapter Tuning:较早期的技术,在层与层之间插入小型的神经网络层(Adapter)。
P-Tuning / Prefix Tuning:不改动模型主体,而是在输入端训练一些“虚拟的提示词向量”(Soft Prompts),相当于训练一个万能的 Prompt。
LoRA (Low-Rank Adaptation):【当前统治级的方法】 LoRA 的出现极大降低了微调门槛。对于一个 7B 的模型,LoRA 可能只需要训练 0.1% - 1% 的参数,这让消费级显卡(如 RTX 3090/4090)微调大模型成为可能。
QLoRA:LoRA 的量化版。先把主模型压缩成 4-bit(大幅降低显存占用),在这个量化模型的基础上加 LoRA。这是目前个人开发者最常用的方案。
LoRA 的设计非常优雅,它完美诠释了数学在工程优化中的力量。直觉假设(Intrinsic Dimension Hypothesis):工程师们发现,大模型虽然参数巨大,但在处理特定任务时,真正起作用的“有效维度”其实很低。也就是说,权重的更新量 ΔW 不需要是满秩的,它可以通过两个极小的矩阵相乘来近似。具体来讲 h = Wx 若进行全参数微调,我们更新的是整个矩阵 W ∈ ℝdout × din,但是LoRA 假设:
大模型微调时,权重的更新 ΔW 通常是低秩的。
所以 LoRA 用一个低秩分解表示微调的更新量:
ΔW = BA
其中:
- A ∈ ℝr × din
- B ∈ ℝdout × r
- r ≪ min (din, dout),如 4、8、16 等
这样:
- 原来一个 dout × din 的大矩阵不动
- 只训练 A, B 这两个“小矩阵”
最终输出变成:
h = Wx + BAx 也可以写为:
h = (W + ΔW)x 但是 W 是冻结的,不会更新。完美!
有监督微调 (SFT - Supervised Fine-Tuning)
有监督微调 (SFT - Supervised Fine-Tuning)是最基础的微调目标。通过喂给模型成对的 (Prompt, Response) 数据教会模型“特定的知识”。它能够让模型学会遵守指令、结构化输出和做有用的任务(总结、回答、解释)
对齐训练(Alignment)
对齐训练就是让“懂很多知识”的 AI,变成一个“符合人类价值观、听懂人话、且安全”的助手。如果说预训练(Pre-training)是让模型“读万卷书”(获得智力),那么对齐训练就是教模型“做人”(符合价值观)。
- RLHF(Reinforcement Learning from Human Feedback)人类反馈强化学习用人类偏好来优化模型行为。
流程是:
SFT(先让模型会说话)
训练奖励模型(Reward Model)
r = Rϕ(x, y)
- 强化学习优化策略(PPO/PPO-ptx)
maxθ𝔼y ∼ πθ[Rϕ(x, y)]
- DPO(Direct Preference Optimization)直接偏好优化,是 RLHF 的无强化学习版。
数学形式: maxθlog σ(β[log πθ(y+) − log πθ(y−)]) 它不需要 PPO,训练更稳定,效果更好。
- 除此之外,还有
- ORPO:用 KL 约束约束偏好
- KTO:OpenAI 小模型对齐方案
- GRPO:聚合奖励
- RLAIF:用模型输出作为偏好
知识增强
- RAG(Retrieval-Augmented Generation)
RAG并不是一种训练方式,也不是训练目标,它只是作为一种“增强方式”,让模型在针对具体领域是避免幻觉和出错。
数学结构:
y = fθ(x, Retrieve(x))
- 蒸馏(Distillation)
蒸馏是让大模型 → 变小模型
数学上:
minθKL(πθ ∥ πteacher)
总结
我们可以把大模型的生命周期看作一个从“通识教育”到“专业就业”的过程,各个技术环节环环相扣:
预训练 (Pre-training) 这是通识教育阶段。模型阅读海量文本,学会了语言的规律和世界的通用知识(如语法、逻辑、常识)。此时的模型像一个博学的“书呆子”,能续写文本,但不懂得如何对话或遵循指令。这是所有大模型能力的基石。
后训练 (Post-training) 这是职业培训阶段,通常包含两个核心步骤:
- SFT (指令微调):教模型“听懂人话”,学会问答、翻译、总结等具体任务形式。
- Alignment (对齐):通过 RLHF 或 DPO 教模型“懂规矩”,符合人类价值观,不胡说八道。
- 经过这一步,Base Model 变成了 Chat/Instruct Model(如 Llama-3-Instruct),这也是我们大多数时候直接调用的模型。
微调 (Fine-tuning) 这是在职深造。当我们有特定的垂直领域需求(如医疗、法律、公司内部代码库)时,通用的 Instruct 模型可能不够用。我们需要用特定领域的数据对模型进行微调(通常使用 LoRA 等高效手段),让它成为某个领域的专家。
知识增强 (RAG) 这是外挂知识库。即使是微调过的专家,也不可能背下所有最新的实时数据(如今天的股价、公司最新的文档)。RAG 就像是给专家配了一个搜索引擎或参考书,让他回答问题时先查阅资料,确保准确无误。
相互依赖关系总结:
- 基座模型 (Base Model) = 预训练
- 聊天模型 (Chat Model) = 基座模型 + SFT + 对齐
- 行业模型 (Domain Model) = 聊天模型 + 领域微调 (Fine-tuning)
- 行业应用 (Application) = 行业模型 + RAG (知识增强) + Agent (工具调用)
大作业二实操指南
现在开始,让我们一步步实操来完成大作业二的基础版,并简单引入一下加分题。
1. 首先是微调数据集准备
咱们的数据集很简单,这一步我们的目标是依赖教材内容来生成问答对,所以完成这一步其实有很多思路,
- 最最最naive的思路:
就是人工去一问一答,每一个章节生成一二十个问答对。这样做的优点达到了老师说的复习的目的,问答对生成结束后肯定学明白了,缺点是费时费力,并且准确率和效果很难保证。 - 稍微进阶一点的思路(适合入门): 这种稍微进阶一点,其实就是将章节内容复制给一个大模型,然后让大模型根据章节内容生成一个高质量的问答对。举例来说,你的prompt可以是:
1 | |
这里其实用到了一个trick,那就是强调了让模型不要无中生有,假设文本中含有一个图片的解释,那么直接问模型就会莫名生成一个结果,尽管问题中完全没提到图表包含哪些信息。也就是需要考虑问题是否独立成立,是否引用不存在的上下文内容,是否超出教材范围,是否符合微调要求(不冗长、不幻觉)。避免大量“坏样本”的生成
- 进阶的做法(pipeline) 这里其实就是用现成的工具,把文本分块,清洗,模型调用,QA生成和数据集封装整个pipeline全部封装在一起了,只需要简单的配置就可以生成高质量的问答对。目前比较好用的工具有easy-dataset,Qanything,llamaindex etc. 这部分工具的好处就是全自动流水,极大节省了时间,但缺点就是需要花费一定的学习的时间成本。
注意到,无论是哪种方式,最终都应该根据微调工具所提供的数据集模板准备好数据集,例如说大多数通用的数据集模板Alpaca的格式就是
1 | |
实际训练时,模型会将instruction和input拼接在一起作为prompt,output作为label,进行微调。
⚠️:这里还需要注意到一点是由于我们的数据集是自行准备的,所以数据集目录下还需要提供一个data_info.json文件(llama-factory工具需要),其中指定了数据集的名称,数据集的地址等信息。例如:
一个数据集的例子:
2
3
4
5
6
7
8
9
10{
"train": {
"file_name": "datasets.jsonl",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
}
}

2. 微调
这里我主要介绍llama-Factory的微调方法,其实准备好数据集后,后面的过程就非常简单了。根据llama-Factory的文档,配置好环境。
1 | |
不少同学可能会卡在这一步,pytorch等一些库容易出问题(⚠️务必注意cuda版本,不然不能使用本地GPU).但这个官方写的教程很清晰了llama-Factory,真遇到问题只能说活用AI了,假设大家成功配置了环境,并且能够运行
llamafactory-cli 命令,接下来就可以愉快玩耍了。
3. 下载大模型
选择一个大模型后,就需要将其下载到本地来进行微调,现在下载大模型的渠道主要是huggingface和modelscope,前者可以访问全球的绝对多数开源模型,后者是国内的模型仓库,如果遇到网络问题可以用modelscope来下载模型。如果是用huggingface,一些模型可能还需要先获得许可(比如说meta的llama模型系列),而国内的开源模型基本不需要认证。
以huggingface为例,下载一个llama模型的命令如下:
首先是登陆huggingface账号,在官网上注册后可以拿到登陆用的token。
1
huggingface-cli login1
huggingface-cli download meta-llama/Meta-Llama-3-8B-Instruct --local-dir ./Llama3-8B-Instruct --include="*"
- meta-llama/Meta-Llama-3-8B-Instruct 是模型仓库名
- –local-dir 设定你要存放模型的目录
- –include=“*” 表示下载全部文件(权重 + 配置 + tokenizer)
当然也可以直接从huggingface官网下载,然后解压到你设定的目录即可。
4.微调
微调这一步就是根据llama-Factory的文档,写好一个训练的yaml文件,其中指定了训练模型的地址,训练用的数据集地址,微调的参数等。
比如官方提供的一个lora微调的模板如下:
1 | |
调整其中的参数,再执行命令就可以美美开始微调了:
1 | |
至于参数是什么意思就自行查阅了。
这里补充一小点,就是其实llama-factory提供了webui,可以一键式微调,非常方便,强烈推荐用这个试一下!
至于Unsloth,它是专门针对 Llama/Mistral 等模型进行极致优化的微调库,速度比 HF 快 2-5 倍,显存占用更低。 如果你选择 Unsloth 赛道,推荐直接使用官方的 Colab Notebook 进行体验,或者本地安装:
1 | |
Unsloth 的使用逻辑和 HF 很像,但需要加载
FastLanguageModel。
5.推理
训练好大模型后,接下来就是检验训练的成果了。也就是将大模型部署起来,然后一问一答,这个过程就是加分题核心优化的地方。但对于基础题来说,llama-factory提供了一个chat的接口,可以直接将lora微调的参数和模型的全参数合并在一起进行推理,并展示聊天UI界面。所以基础题其实很简单,真正写代码的地方并不多,准确地说,甚至不需要写代码。
至于加分题,就需要用到专门的推理引擎来部署,推理引擎的主要任务就是通过优化,让模型的推理速度更快,显存占用更低。可以通过优化其中的部分算子实现特定模型的加速,所以就是狠狠优化就行了😋!
6.总结
根据我的实操,一个7B的模型实际训练的时候峰值甚至会达到50G+的显存,比我想象中还要多。但实际推理的时候只需要用到15GB显存。这里需要说明的一点是,显存占有那么高是因为我没有加量化,如果加了量化可能会更低。至于量化是什么,简单来说就是数据精度变少,比如bf16,fp16,fp8等,所需的存储空间也会变少。~~对于课程任务而言,7B的模型量级是足够了的~~,实际上,3B甚至更小就完全可以胜任课程任务了。因为只有300道测试题,所以准确率只要不是太低,应该都是可以过的。并且,参数规模越小,模型推理也会更快。
2025-12-25 更新:
- 增加了微调后模型的上传方法
- 解释各模版文件的含义
- 如何提交
GPU大作业二(补充)
第一版发布后,不少同学都在问后面怎么搞。由于助教已经公布了评测系统和数据集示例,现在补充更新一下后续的流程。我主要说一下提交作业的流程,以及一些可能需要补充的内容。
1. 上传模型
在微调完成后,需要将模型上传到模型仓库上,比如说huggingface,modelscope等。由于国内访问huggingface可能会有网络问题,评测时可能拉取不到模型权重,所以推荐使用modelscope或者huggingface的国内镜像。这里以modelscope为例进行介绍。
假设上述llama-factory的微调后保存目录为saves/qwen2.5-3b-instruct/lora/,一般来说,该目录下会包括多个文件,比如:
- config.json
- model.safetensors
- tokenizer.json
- tokenizer_config.json
- vocab.json
其中config.json和model.safetensors是模型权重,tokenizer.json和tokenizer_config.json是tokenizer,vocab.json是词汇表。接下来需要将这些文件上传到modelscope上。
这里需要注意的一点是,如果使用的是lora微调,那么还首先需要与原本的模型进行merge,然后才能上传到modelscope上。merge的方法是直接使用llama-factorywebui的export功能,选择lora模型,然后选择原本的模型,点击export按钮,即可得到合并后的模型。
如果是使用full微调,就直接上传full微调后的模型即可
拿到微调好的模型后,下一步就是将其上传到modelscope上,创建账号后在个人主页创建模型仓库并选择非公开。名字任意起,然后在个人主页的账号设置中,找到访问令牌,记住这个token,后面需要用到。
现在安装modelscope库,并实现下述的上传脚本: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16from modelscope.hub.api import HubApi
# 1. 登录
# 将 'YOUR_ACCESS_TOKEN' 替换为你第一阶段获取的 Token
api = HubApi()
api.login('YOUR_ACCESS_TOKEN')
# 2. 推送模型
# model_id format: '你的用户名/模型名称' (如果模型库不存在,会自动创建)
# model_dir: 本地模型文件夹的路径
api.upload_folder(
repo_id="YOUR_USERNAME/YOUR_MODEL_NAME",
folder_path="./saves/your_model_name/lora",
commit_message="upload model weights",
repo_type="model"
)
2. 提交作业
助教已经在详细地说明了如何提交及评测,请参考大作业二说明。这里提供了三份不同平台的提交模板,它们都包括以下几个文件:
- download_model.py
- Dockerfile
- requirements.txt
- server.py
- .gitignore
其中download_model.py是下载模型权重和tokenizer的脚本,即我们上一步上传的模型。Dockerfile是构建docker镜像的文件,关于Docker的详细介绍请参考我之前写的一个非完整博客容器核心原理。注意到,摩尔线程中使用的是FakeDockerfile,这是一个虚拟的docker镜像构建文件,实际运行时会自动下载模型权重和tokenizer。因为摩尔线程的平台本身就是一个docker镜像,所以不能再构建docker镜像。 requirements.txt是安装依赖的文件,如果使用的是并行科技,那么实际上不需要transfomers,tokenizers等库,因为平台本身镜像中已经提供了这些库,手动指定反而会报错。
server.py是我们真正需要操作的脚本,这个脚本的作用很简单,就是启动一个fastapi服务器,然后接收一个prompt,使用加载的模型进行推理,并返回结果。实现推理加速也是在这个脚本,比如说可以在这里添加vllm,sglang等进行推理加速。你需要做的就是保证上述的模型上传没问题,同时download_model.py下载的模型路径正确。并在server.py中指定模型路径,那么正常来说就可以正常评测了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99import torch
from fastapi import FastAPI
from pydantic import BaseModel
import os
os.environ["TRANSFORMERS_OFFLINE"] = "1"
from transformers import pipeline, set_seed
from transformers import AutoModelForCausalLM, AutoTokenizer
import socket
def check_internet(host="8.8.8.8", port=53, timeout=3):
try:
socket.setdefaulttimeout(timeout)
socket.socket(socket.AF_INET, socket.SOCK_STREAM).connect((host, port))
return True
except Exception:
return False
# 本地模型路径
LOCAL_MODEL_PATH = "./local-model"
# --- 网络连通性测试 ---
internet_ok = check_internet()
print("【Internet Connectivity Test】:",
"CONNECTED" if internet_ok else "OFFLINE / BLOCKED")
# --- 模型加载(从本地加载,无需网络)---
print(f"从本地加载模型:{LOCAL_MODEL_PATH}")
# 手动加载本地模型和tokenizer
tokenizer = AutoTokenizer.from_pretrained(LOCAL_MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(LOCAL_MODEL_PATH)
# 初始化pipeline(使用本地模型)
generator = pipeline(
'text-generation',
model=model,
tokenizer=tokenizer,
device='cuda'
)
set_seed(42)
# --- API 定义 ---
# 创建FastAPI应用实例
app = FastAPI(
title="Simple Inference Server",
description="A simple API to run a small language model."
)
# 定义API请求的数据模型
class PromptRequest(BaseModel):
prompt: str
# 定义API响应的数据模型
class PredictResponse(BaseModel):
response: str
# --- API 端点 ---
@app.post("/predict", response_model=PredictResponse)
def predict(request: PromptRequest):
"""
接收一个prompt,使用加载的模型进行推理,并返回结果。
"""
# raise RuntimeError(request.prompt)
# 单轮 Prompt
prompt = f"Q: {request.prompt}\nA:"
# 使用 max_new_tokens + return_full_text=False 来防止重复 prompt
model_output = generator(
prompt,
max_new_tokens=200, # 生成长度只限制新增内容
num_return_sequences=1,
do_sample=False, # 关闭采样,稳定输出
return_full_text=False, # 只返回新增内容,非常关键!
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
generated = model_output[0]["generated_text"].strip()
# 截断可能继续生成的 "Q:" 或下一轮问话
for sep in ["\nQ:", "\nQ ", "Q:", "\nQuestion:", "\n\nQ:"]:
pos = generated.find(sep)
if pos != -1:
generated = generated[:pos].strip()
break
# 防止答案开头重复问句
if generated.startswith(request.prompt):
generated = generated[len(request.prompt):].strip(" \n:.-")
return PredictResponse(response=generated)
@app.get("/")
def health_check():
"""
健康检查端点,用于确认服务是否启动成功。
"""
return {"status": "ok"}
下载模型的脚本参考: 1
2
3
4
5
6
7
8
9from modelscope import HubApi
from modelscope import snapshot_download
# login to ModelScope
api=HubApi()
api.login('YOUR_ACCESS_TOKEN')
# download your model, the model_path is downloaded model path.
snapshot_download(model_id='YOUR_USERNAME/YOUR_MODEL_NAME', local_dir='./model')
注意这里的model_id是模型仓库名,而不是模型ID。
3. 评测
评测的流程是,当你将上述文件均按照大作业二的说明提交后,将仓库地址填写到评测系统的模型地址中,然后评测系统就会自动拉取代码,构建镜像,并调用predict接口来获取对应测试集问题的回复,如果回复与评测集答案相似,那么准确率就会很高。这里是用的rouge-L,很神奇,但没招,理论上只有回复跟答案一模一样性能得分才可能高。